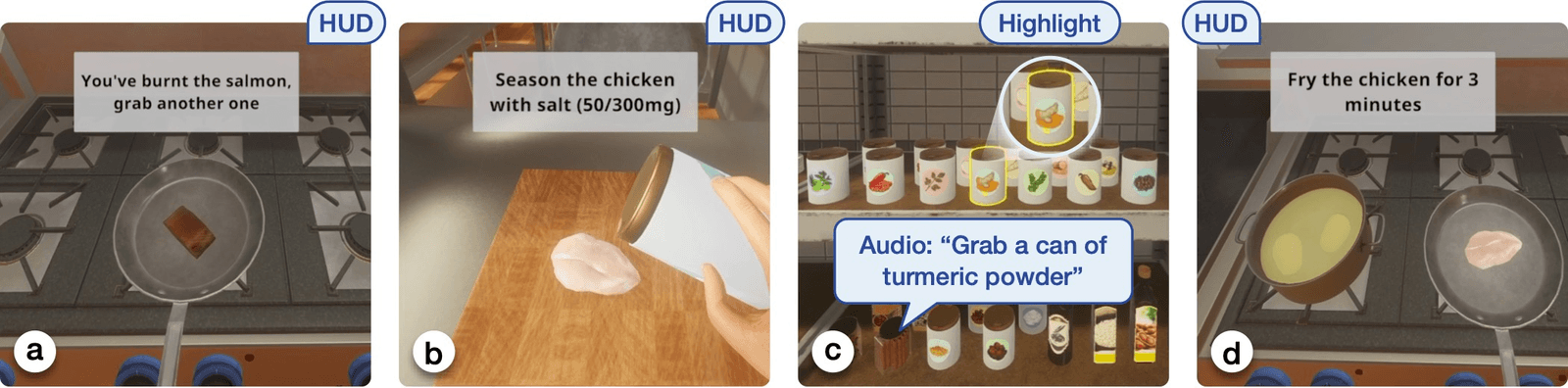
Most guidance breaks the moment you do. Miss a step and the instructions march on without you. AMMA adapts the interface to the person, switching between HUD, object highlighting, and speech from a live user model. I built the multimodal pipeline and the engine bridge that made it run inside a commercial VR game.
~22% faster task completion · lower cognitive load across all NASA-TLX dimensions · personalization gain p<.001
Problem
Guidance that breaks the moment you do
Step-by-step instructions assume a perfect user: right order, no mistakes, one way of understanding. Real people burn the salmon, work out of sequence, and read a HUD where someone else needs to hear the step. When guidance can’t adapt, it stops being help and starts being noise.
3ways to deliver a step (HUD, highlight, speech) that should depend on the moment
1rigid script is all most guidance systems actually offer
0recovery paths when a user makes an irreversible mistake
The research question: how does guidance move past a fixed script to adapt to mistakes, differing physical abilities, and individual communication preferences, in real time?
Approach
Adapt the interface, not just the instruction
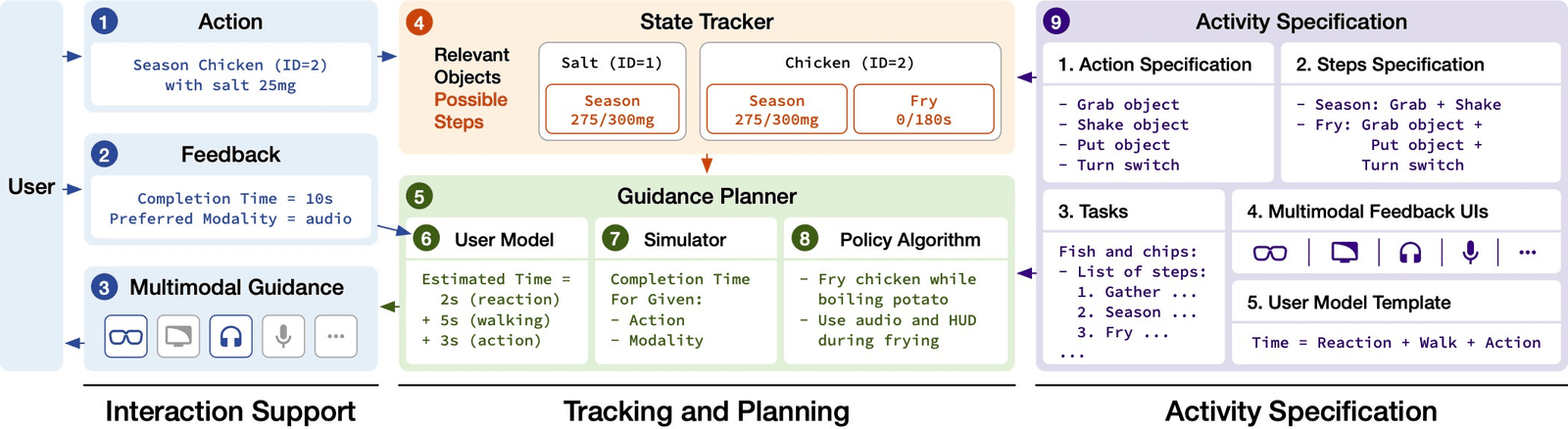
AMMA generates the interface from a step list by tracking what the user has actually done and learning a personal model of how they work, then choosing which modality to fire and when. The hard part isn’t the idea; it’s making it run honestly inside a real VR task, where the system has to watch every grab, pour, and seasoning and react before the moment passes.
Process & artifacts
Building the adaptive layer
I owned the layer that turns a tracked state into the right cue at the right time, and the bridge that let research logic drive a closed commercial game.
Multimodal pipelineBuilt the logic that switches between a HUD, 3D object highlighting, and speech, deciding by task type and the user’s learned preference, and prioritizing time-critical cues like “Flip” or “Stop” so instructions never stack.
Speech + languageBuilt a Text-to-Speech pipeline on Azure Cognitive Services with contextual interrupts, plus parsing that turns raw recipe data (“0/300mg”) into natural speech (“300 milligrams”) to hold immersion.
Engine bridgeCo-developed a C#/BepInEx plugin that injects research logic into Cooking Simulator VR, relaying every action to a Python state tracker over a bi-directional TCP socket with minimal latency.
Research instrumentationBuilt pickle-based logging for perfect post-study replay and a study CLI to start/stop sessions, reset positions, and manage continuous speech recognition.
The full architecture: interaction support feeds a state tracker and a guidance planner (user model, simulator, policy) driven by an activity specification. My work lived in the interaction-support and tracking layers.
Impact
Faster, lighter, and tuned to the person
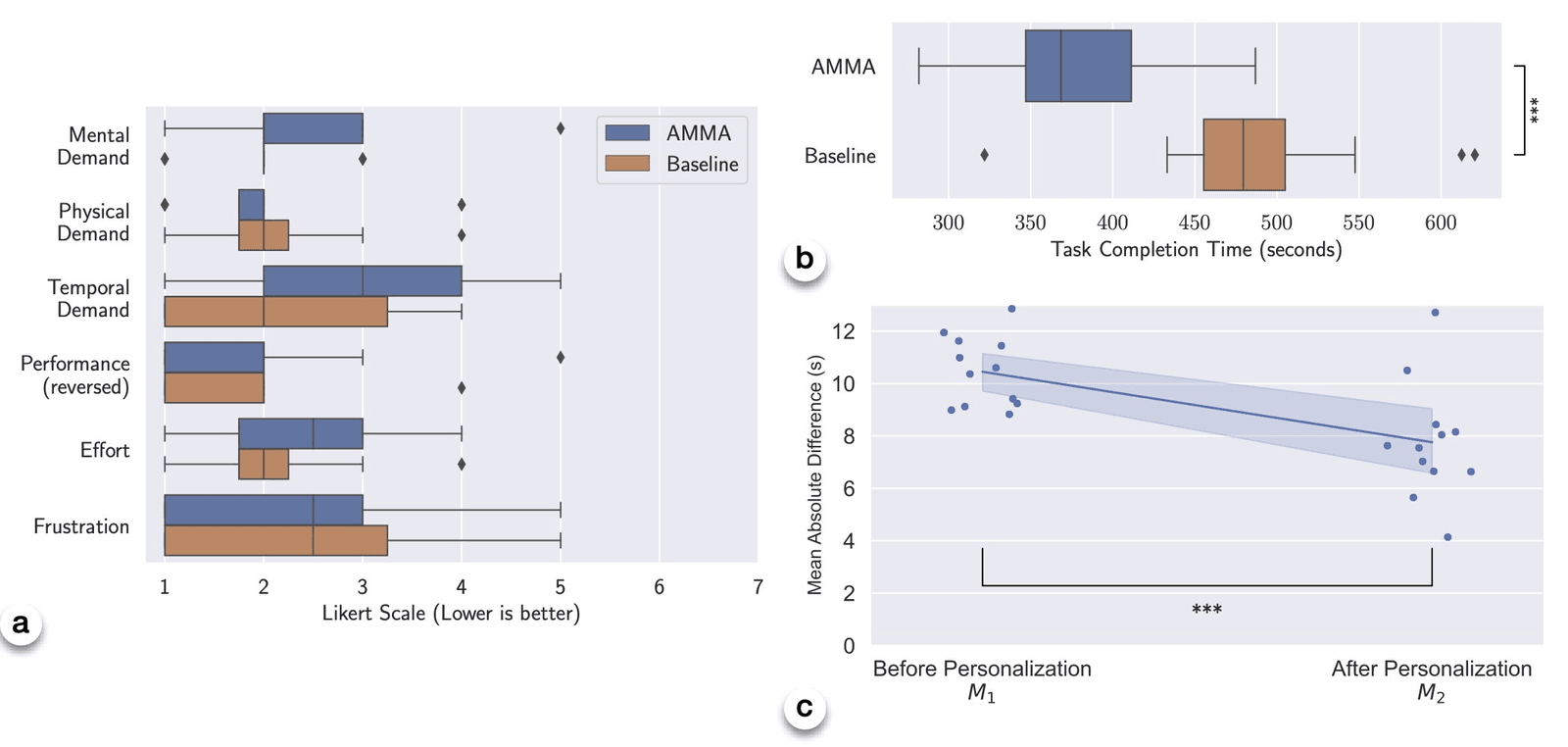
~22%Reduction in task-completion time versus the baseline guidance system
NASA-TLXLower self-reported load across every dimension: mental, temporal, effort, frustration
p<.001Personalization measurably improved as the user model converged on each participant
IEEE VR 2024Published as a full conference paper (pp. 892–902); I am third author
NASA-TLX favored AMMA across the board; task time dropped ~22%; and the user model’s error shrank significantly after personalization.
My role
I joined AMMA as a Stanford CURIS undergraduate researcher in Summer 2022 and am third author on the IEEE VR 2024 paper. I built the adaptive multimodal pipeline (HUD/highlight logic, the Azure TTS pipeline, and the language parsing) and the research instrumentation (logging + study CLI), and co-developed the C#/BepInEx engine bridge. The state tracker and the study design were team work, led by Jackie (Junrui) Yang and advised by Monica S. Lam and James A. Landay.
Reflections & takeaways
The lesson that stuck wasn’t about adaptivity. It was about restraint. The fastest way to overwhelm someone in VR is to give them more guidance, so the real engineering was deciding what not to surface: suppressing redundant cues, interrupting cleanly when a time-critical step arrived, and keeping speech natural enough that it didn’t break immersion. And making research logic drive a closed commercial game (C# to Python over a socket, hooking low-level events in real time) taught me that the unglamorous bridge is often what decides whether an idea can be studied at all.
Jackie (Junrui) Yang, Leping Qiu, Emmanuel Angel Corona-Moreno, Louisa Shi, Hung Bui, Monica S. Lam, and James A. Landay. 2024. “AMMA: Adaptive Multimodal Assistants Through Automated State Tracking and User Model-Directed Guidance Planning.” In 2024 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Orlando, FL, USA, pp. 892–902.